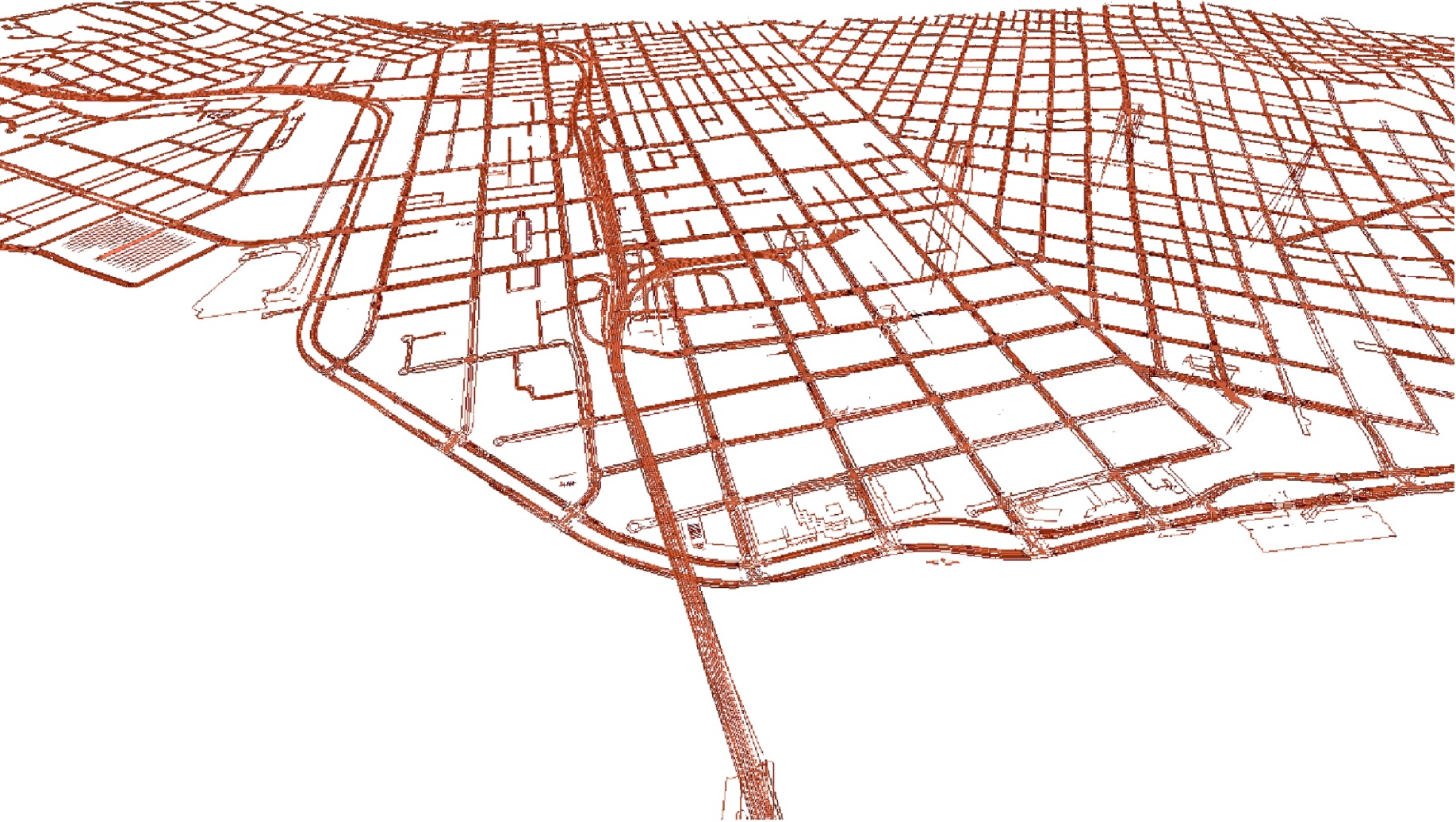
HD Mapping & Localization
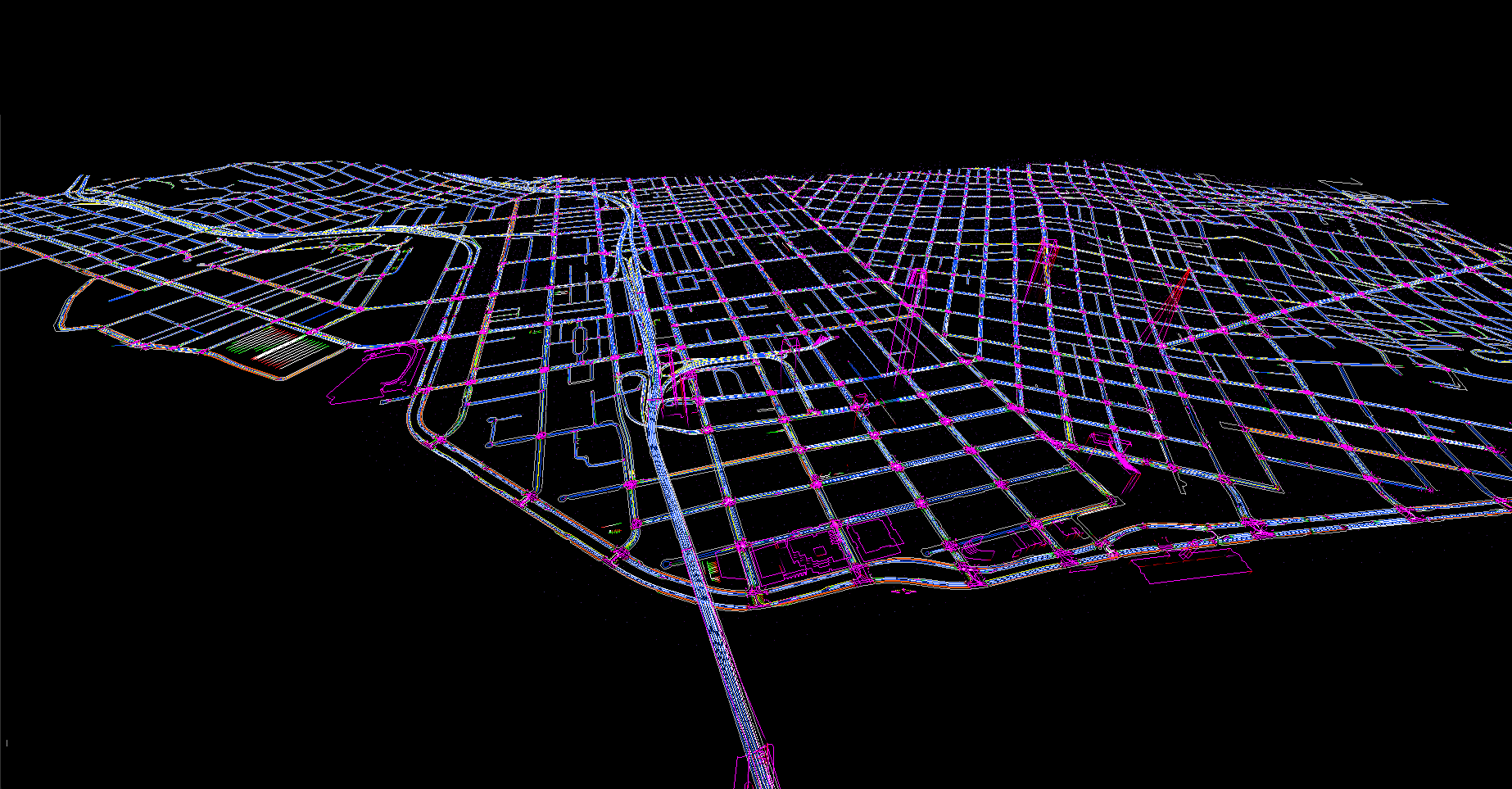
United States
15 cm – 20 cm absolute accuracy

Europe
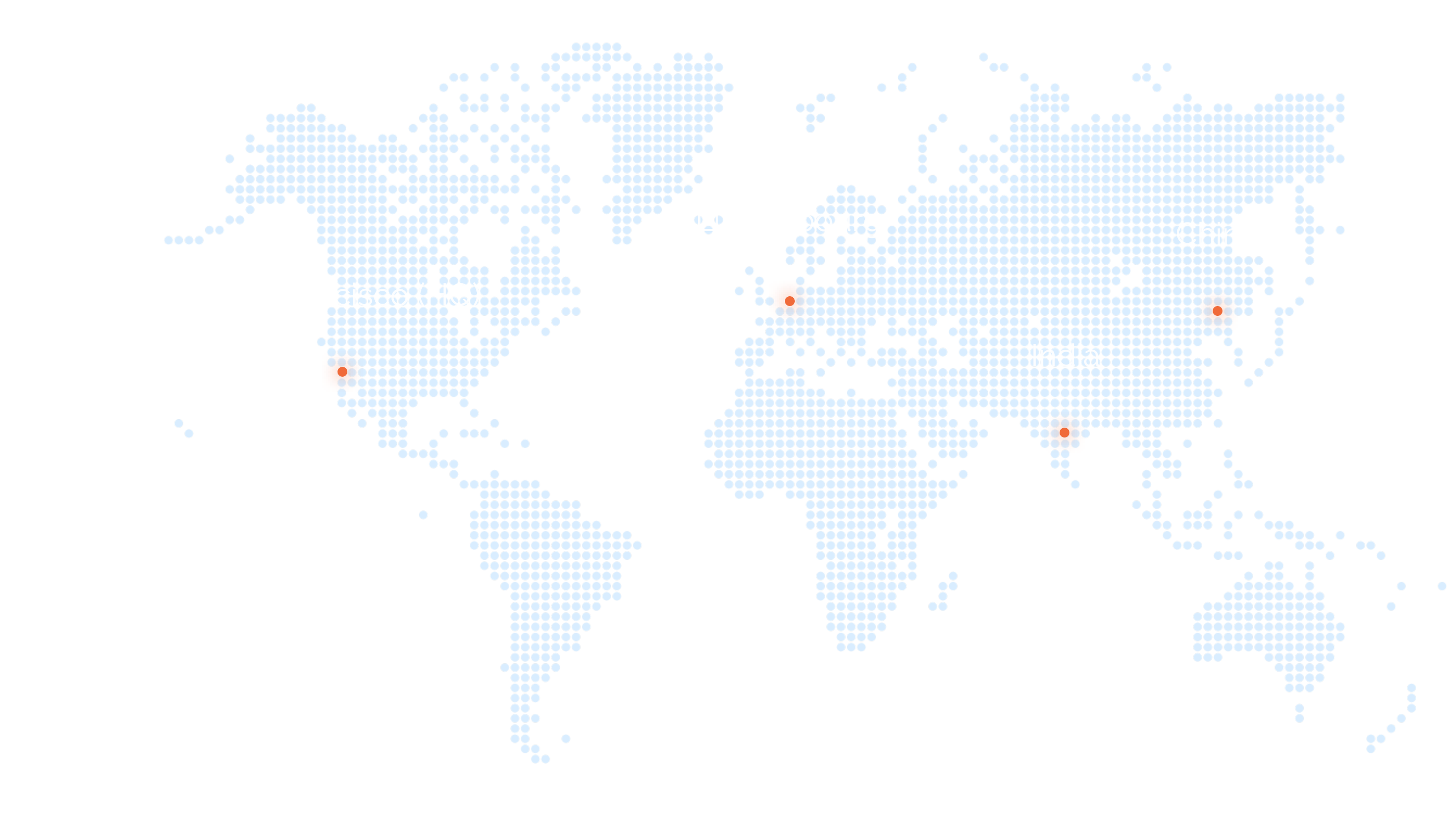
Scaling precision across continents
Asia
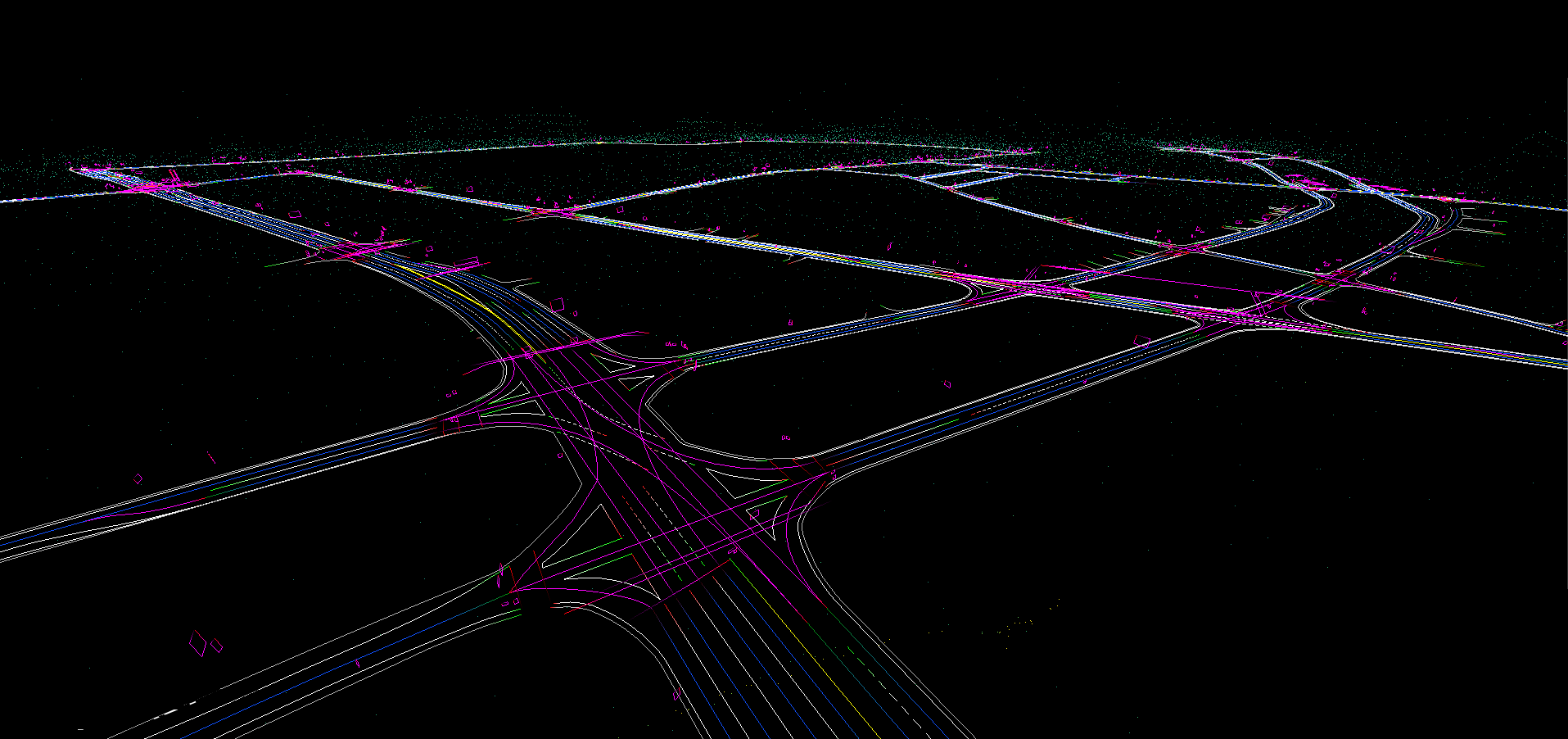
High-fidelity point cloud processing
Autonomous Vehicle Routing

Global Presence
15 cm – 20 cm absolute accuracy
Scaling precision across continents
High-fidelity point cloud processing